1、 *** 一: 通过输入网址“https://”,进入百度搜索引擎页面。
2、亲,你好。你的提问就是有问题的,不管是什么样的企业站,不管这个企业站有多垃圾,有多简单,它都是有FTP的,没有ftp,网站的程序代码文件放到哪去?robots协议就是在ftp里,这个我觉得你还是跟做你网站的技术好好沟通。
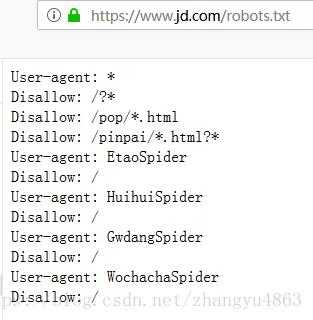
3、robots协议就是在ftp里,这个我觉得你还是跟做你网站的技术好好沟通。不过一般要是网站没多大问题的,都是没有robots协议的,这个是后期网站出现一些404页面而再写的。
4、打开您的网页浏览器,如Chrome,Firefox等,输入b站的网址“”。在浏览器地址栏的末尾输入“/robots.txt”,即“”,然后按下回车键。
Googlebot 可识别称为“Allow”的 robots.txt 标准扩展名。其他搜索引擎的漫游器可能无法识别此扩展名,因此请使用您感兴趣的其他搜索引擎进行查找。“Allow”行的作用原理完全与“Disallow”行一样。
Robots简单来说就是搜索引擎和我们网站之间的一个协议,用于定义搜索引擎抓取和禁止的协议。
robots是一个协议,是建立在网站根目录下的一个以(robots.txt)结尾的文本文件,对搜索引擎蜘蛛的一种限制指令。
robots.txt应放置于网站的根目录下。如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,或者使用robots元数据(Metadata,又称元数据)。
最简单的robots.txt只有两个规则:User-agent:指定对哪些爬虫生效 Disallow:指定要屏蔽的网址 接下来以亚马逊的robots协议为例,分析其内容。首先,先来分析亚马逊对于网络爬虫的限制。
robots.txt语法有三个语法和两个通配符。三个语法:首先要定义网站被访问的搜索引擎是那些。
1、登录网站。因为这个网站的robots.txt文件有限制指令(限制搜索引擎抓取),所以系统无法提供这个页面。我该怎么办?原因:百度无法抓取网站,因为其robots.txt文件屏蔽了百度。 *** :修改robots文件并取消对该页面的阻止。
2、可能违法。其爬虫下载数据,一般而言都不违法,因为爬虫爬取的数据同行也是网站上用户打开页面能够看到的数据,但是如果符合下列条件的网站进行强行数据采集时,会具有法律风险。可能会造成侵犯隐私权的违法行为。
3、Robots.txt - 禁止爬虫robots.txt用于禁止网络爬虫访问网站指定目录。robots.txt的格式采用面向行的语法:空行、注释行(以#打头)、规则行。规则行的格式为:Field: value。常见的规则行:User-Agent、Disallow、Allow行。
4、根据查询相关 *** 息显示,爬虫工具可以用来采集图像测速和热敏设备的数据。爬虫可以抓取到所需的数据,并可以将数据存储在数据库中以供以后使用。另外,爬虫也可以自动抓取网站上的信息,从而帮助分析网站的行为。
5、采集,一般指定向将指定范围的网页内容拷贝下来。网络爬虫,包含采集功能,但有一定的自主性,可以自主决定要访问的网页,看起来带有一定的“智能”性,但都是按事先拟定的程序逻辑运行。
主动提交网站链接 当更新网站页面或者一些页面没被搜索引擎收录的时候,就可以把链接整理后,提交到搜索引擎中,这样可以加快网站页面被搜索引擎蜘蛛抓取的速度。
最直接的办法就是在站内开放链接上统一url规范,不要给你不想收录的二级域名任何入口,然后不断更新一些信息,搜索引擎会逐渐自然的淘汰二级域名。
*** 六:网站随机采用不同模版 分析:因为采集器是根据网页结构来定位所需要的内容,一旦先后两次模版更换,采集规则就失效,不错。而且这样对搜索引擎爬虫没影响。适用网站:动态网站,并且不考虑用户体验。
1、robots.txt文件是一个文本文件,使用任何一个常见的文本编辑器,比如Windows系统自带的Notepad,就可以创建和编辑它 。robots.txt是一个协议,而不是一个命令。robots.txt是搜索引擎中访问网站的时候要查看的之一个文件。
2、Robots是一个英文单词,对英语比较懂的朋友相信都知道,Robots的中文意思是机器人。
3、Robots协议通常被称为是爬虫协议、机器人协议,主要是在搜素引擎中会见到,其本质是网站和搜索引擎爬虫的沟通方式,用来指导搜索引擎更好地抓取网站内容,而不是作为搜索引擎之间互相限制和不正当竞争的工具。