1、蜘蛛在爬去网站页面之前,会先去访问网站根目录下面的一个文件,就是robots.txt。这个文件其实就是给“蜘蛛”的规则,如果没有这个文件,蜘蛛会认为你的网站同意全部抓取网页。
2、robots.txt是搜索引擎中访问网站的时候要查看的之一个文件。Robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。
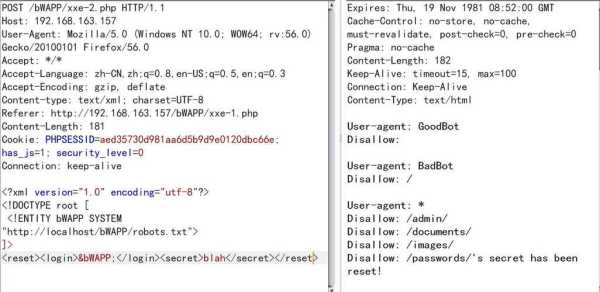
3、Robots.txt 是个纯文本文件,当一个搜索robot访问一个站点时,他首先爬行来检查该站点根目录下是否存在robot.txt,如果存在,根据文件内容来确定访问范围,如果没有(为Null),搜索robot就沿着链接抓取。
4、robots.txt文件会告诉蜘蛛程序在服务器上什么文件是可以被查看的什么文件是不允许查看的。
5、登录网站。因为这个网站的robots.txt文件有限制指令(限制搜索引擎抓取),所以系统无法提供这个页面。我该怎么办?原因:百度无法抓取网站,因为其robots.txt文件屏蔽了百度。 *** :修改robots文件并取消对该页面的阻止。
注意:User-Agent:后面要有一个空格。在robots.txt中,键后面加:号,后面必有一个空格,和值相区分开。2)Disallow键 该键用来说明不允许搜索引擎蜘蛛抓取的URL路径。
robots.txt 文件应该放置在网站根目录下(/robots.txt)。
找到网站死链后,到百度站长平台提交死链,等待百度删除即可。
robots.txt 是一个纯文本文件,在这个文件中网站管理者可以声明该网站中不想被robots访问的部分,或者指定搜索引擎只收录指定的内容。
您可以在您的网站中创建一个纯文本文件robots.txt,在这个文件中声明该网站中不想被robot访问的部分,这样,该网站的部分或全部内容就可以不被搜索引擎收录了,或者指定搜索引擎只收录指定的内容。
robots.txt文件中不需要专门屏蔽CSS *** 等文件 因为robots.txt只是给搜索引擎蜘蛛爬去做限制的,告诉蜘蛛哪些文件夹或路径不要去爬取。
这个文件是针对搜索引擎设置的文件。Robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。 Disallow:这个词就是禁止搜索引擎访问的意思。
robots.txt是搜索引擎中访问网站的时候要查看的之一个文件。Robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。
搜索引擎爬去我们页面的工具叫做搜索引擎机器人,也生动的叫做“蜘蛛”蜘蛛在爬去网站页面之前,会先去访问网站根目录下面的一个文件,就是robots.txt。
1、如果你想了解dz论坛(Discuz论坛)的Robots.txt设置,你可以采取以下步骤: 登录dz论坛的后台管理系统。 导航到“论坛设置”或类似的选项。 在设置选项中找到“Robots文件”或相关的设置选项。
2、WordPress站点默认在浏览器中输入:你的域名/robots.txt,会显示如下内容:User-agent: *Disallow: /wp-admin/Disallow: /wp-includes/这是由WordPress自动生成的,意思是告诉搜索引擎不要抓取后台程序文件。
3、首先,我们需要创建一个robots.txt文本文件,然后在文档内设置好代码,告诉搜索引擎我网站的哪些文件你不能访问。
在 robots.txt 文件中,如果有多条- User-agent 记录说明有多个 robot 会受到 robots.txt 的限制,对该文件来说,至少要有一条 User-agent 记录。
Robots.txt文件的格式:Robots.txt文件的格式比较特殊,它由记录组成。这些记录通过空行分开。其中每条记录均由两个域组成:1) 一个User-Agent(用户 *** )字符串行;2) 若干Disallow字符串行。
Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /private/ 因为一些系统中的URL是大小写敏感的,所以Robots.txt的文件名应统一为小写,即robots.txt。robots.txt应放置于网站的根目录下。
robots.txt必须放置在一个站点的根目录下,而且文件名必须全部小写。